Table of Contents
Overview and Objective
This project is a pilot initiative developed in 2022, designed to establish a foundational model for facial recognition that can accurately identify and verify faces. By harnessing the power of deep learning techniques, the model aspires to deliver highly accurate and efficient facial recognition capabilities. The ultimate goal is to create a scalable solution and a fully functional deep learning workflow that can be utilized to advance CNN (Convolutional Neural Network) projects and any computer vision application.
Motivation and Inspiration
This facial recognition project is inspired by the remarkable capabilities of the human eye and brain, which can effortlessly detect and recognize multiple objects and faces simultaneously. In everyday situations, humans can quickly identify individuals across various environments, regardless of lighting, angles, or distractions, thanks to the brain's ability to process complex visual data into recognizable patterns. This natural ability forms the foundation of my project, which aims to replicate and enhance human facial recognition using advanced technology.
By mimicking the human visual system, my goal is to create a highly accurate and efficient facial recognition system that excels in dynamic real-world scenarios, bridging the gap between human perception and artificial intelligence. On the other hand, faces are among the most challenging objects to recognize due to the vast similarities among human faces. Even small facial features can resemble those of other individuals. If this deep learning model can achieve high accuracy despite the many variations in human facial features, I believe that this algorithm and deep learning model can be applied to a wide range of objects beyond just facial recognition.
Workflow
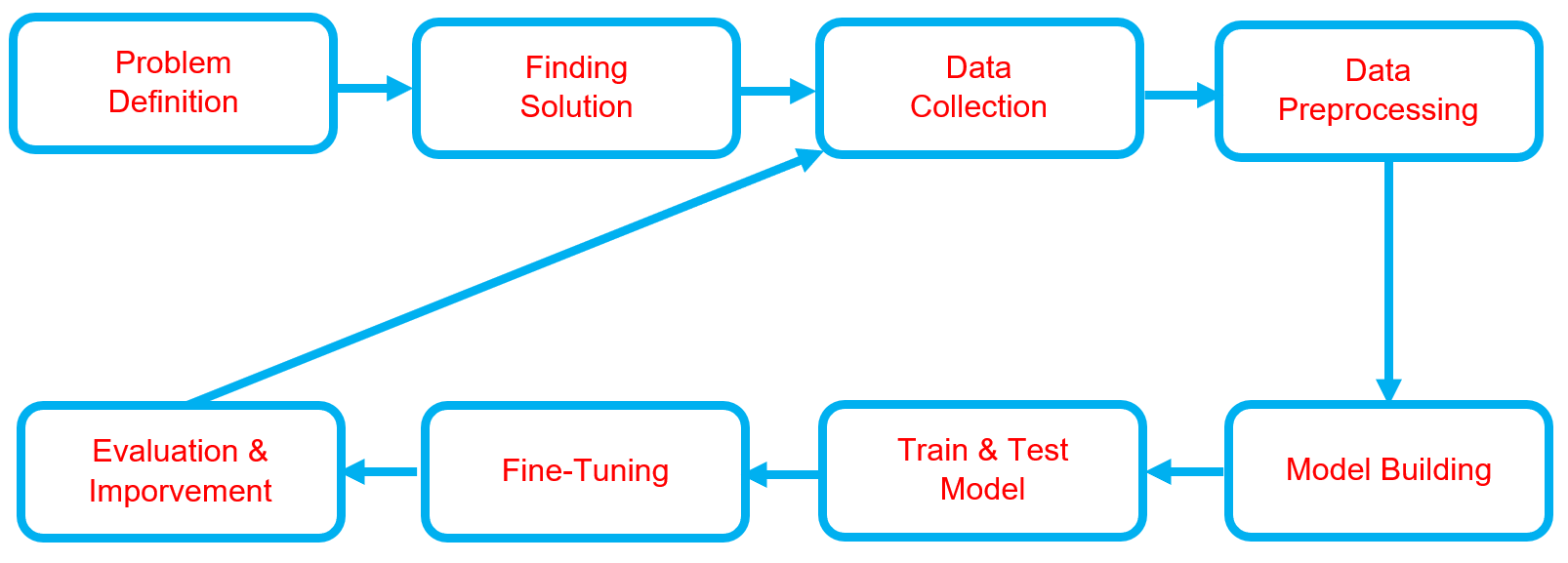
Below is the workflow on how my project works
-
Problem Definition
- Clearly define the problem that needs to be solved.
- Clearly define the problem that needs to be solved.
-
Finding Solutions
- List all potential solutions and select one for implementation.
- Set objectives (e.g., classification accuracy, minimizing prediction errors) and constraints (e.g., time, hardware limitations).
- Develop a plan that outlines the expected outcomes.
-
Data Collection
- Gather and prepare relevant datasets aligned with the problem.
- If batch datasets are unavailable, develop a data collection process like web scraping.
-
Data Preprocessing
- Clean and sort relevant datasets.
- Handle missing data or outliers.
- Perform data augmentation.
- Split the data into training, validation, and test sets.
-
Model Building
- Select a deep learning model architecture based on the problem (e.g., CNN for images, RNN/LSTM for sequential data, Transformer for NLP).
- Configure layers (convolutional, dense, recurrent, etc.), activations, and connectivity.
- Choose an optimizer (e.g., Adam, SGD, RMSProp).
- Set hyperparameters such as learning rate, batch size, and number of epochs.
-
Train & Test Model
- Train the model, setting targets for accuracy, loss, and other performance metrics.
- Test the model using the test dataset to evaluate its performance.
- Inspect feature maps and filters.
- Conduct real-world testing with external datasets to ensure the model's accuracy and applicability.
-
Fine-Tuning
- Hyperparameter Tuning: Adjust learning rate, batch size, number of layers, etc., to enhance performance.
- Regularization: Apply techniques like dropout, weight decay, or L2 regularization to avoid overfitting.
- Transfer Learning: Fine-tune pre-trained models on new datasets if the original task is similar.
-
Evaluation & Improvement
- Evaluate inputs, processes, outputs, and outcomes.
- Identify challenges.
- Gain insights.
- Implement necessary improvements by addressing challenges, adding new features, or refining results based on evaluation feedback.
- Develop a plan for future enhancements.
Solution and Technology Stack
Used tools:
- Python library :






- Hardware : Laptop Acer Predator Helios 300, Intel-12700H, 48 GB Ram, Gen4 SSD, RTX3070Ti Laptop GPU, 8 GB Vram
Project Details and Results
-
Data Collection
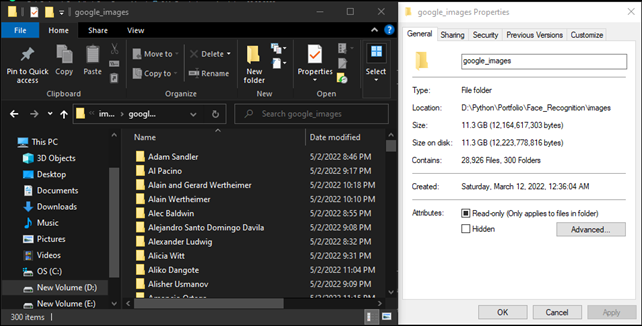
I encountered difficulties in gathering data through Kaggle.com, so the solution was to create a bot. I developed an automation bot using the Selenium module to collect facial images. The bot's task is to gather images by using celebrity names as keywords, searching through Google Images, and downloading as many images as needed (100 images per keyword in this case). To speed up the data collection process, I implemented multi-threading, running 10 bots simultaneously, each with different keyword tasks. For the initial data collection, I used 300 celebrity names as keywords.
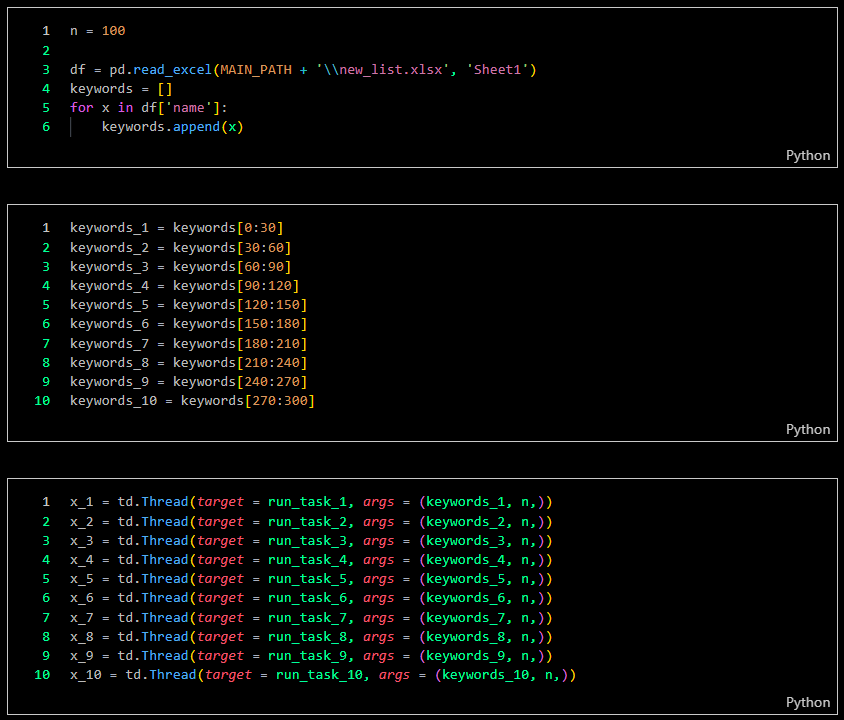
In total, I collected around 28,926 image files, organized into folders based on the respective keywords.
-
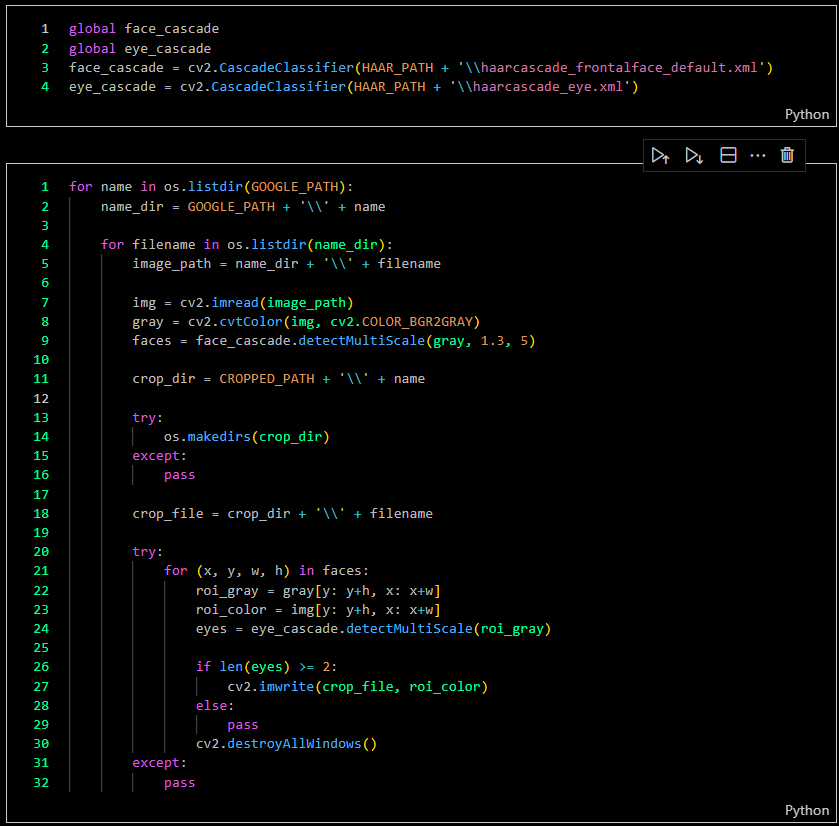
Cropping Images
I encountered an issue where the downloaded images were random, so I needed to ensure that I was specifically getting facial images. The solution was to create an automation process that could crop only the faces using OpenCV, leveraging the Haar Cascade method.

-
Data Cleaning
-
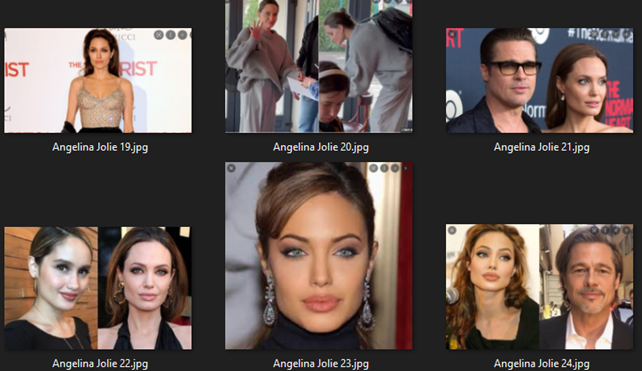
At this stage, I had to manually verify whether the collected facial images were correct, as sometimes the images included pictures of other individuals. I needed to remove any faces that did not match the criteria.
-
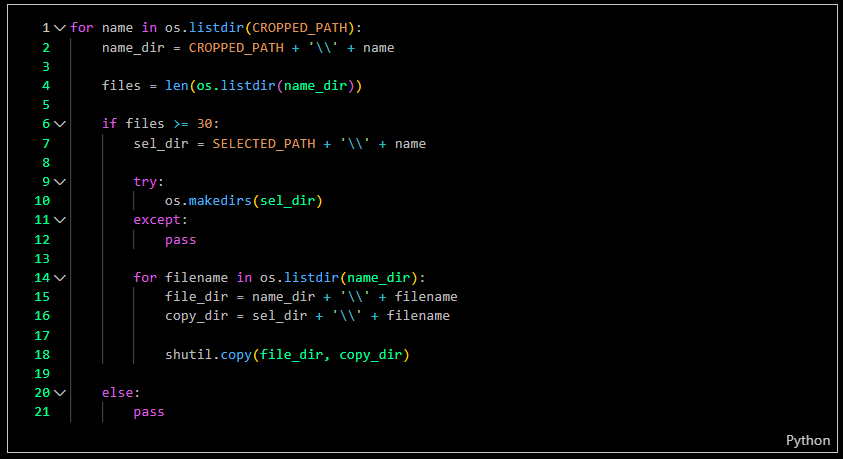
In this step, I calculated the cropped images to ensure the sample set was heterogeneous. The folder of cropped images needed to contain 50 images; once a folder met this requirement, my code would copy the images to another directory.
-
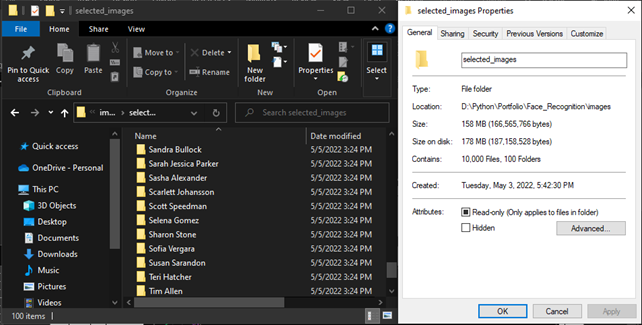
At this point, I had to manually select 100 folders to be used as samples.
-
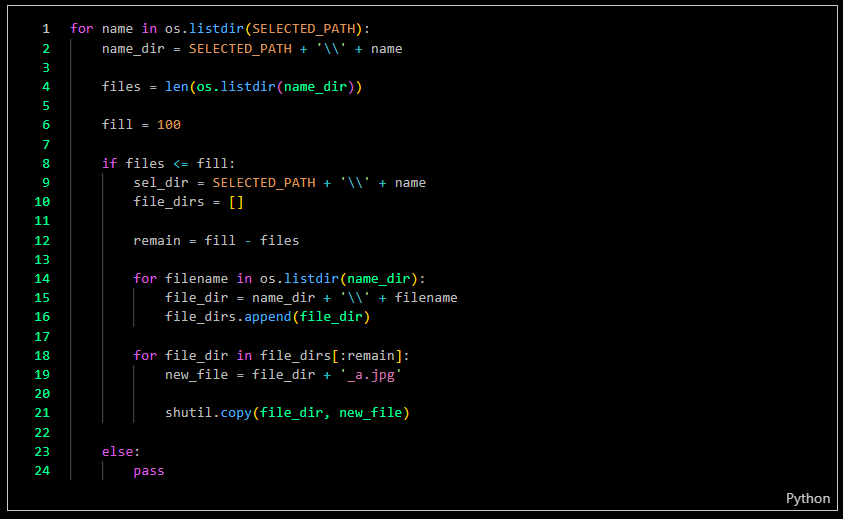
Finally, each folder of images needed to have 100 sample images. To achieve this, I created code that could duplicate images as necessary.
-
-
Training Model
-
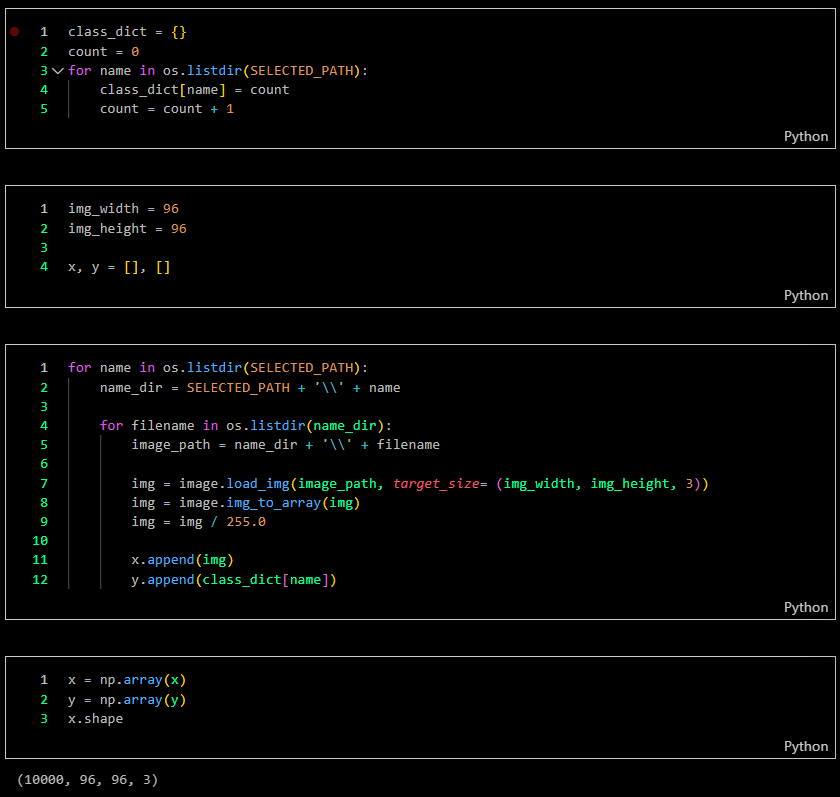
I loaded the samples into an array with 96 x 96 pixels as my input tensor, consisting of 10,000 samples. In this case, the input tensor represents celebrity face images, and the output tensor corresponds to 100 celebrity names.
-
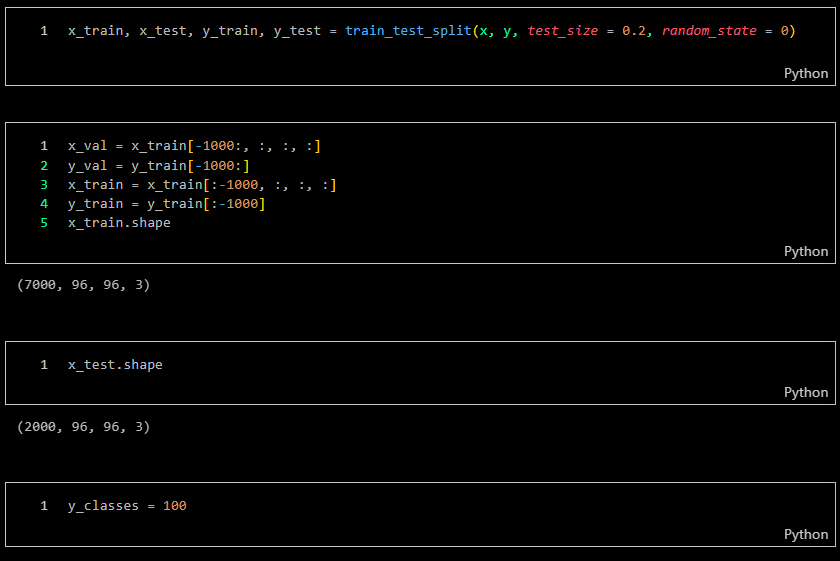
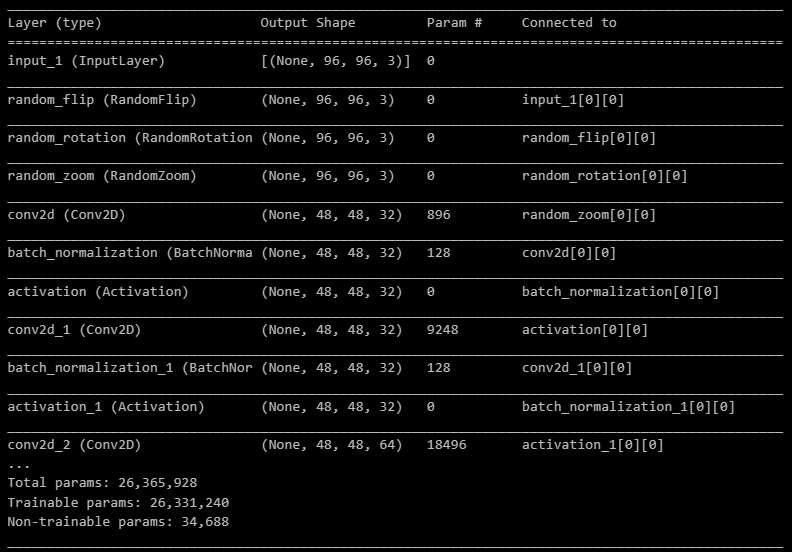
I used 10,000 images as my sample set, with 7,000 images allocated for training (70%), 2,000 images for testing (20%), and 1,000 images for validation (10%). The deep learning CNN models will use 26 million trainable parameters.
-
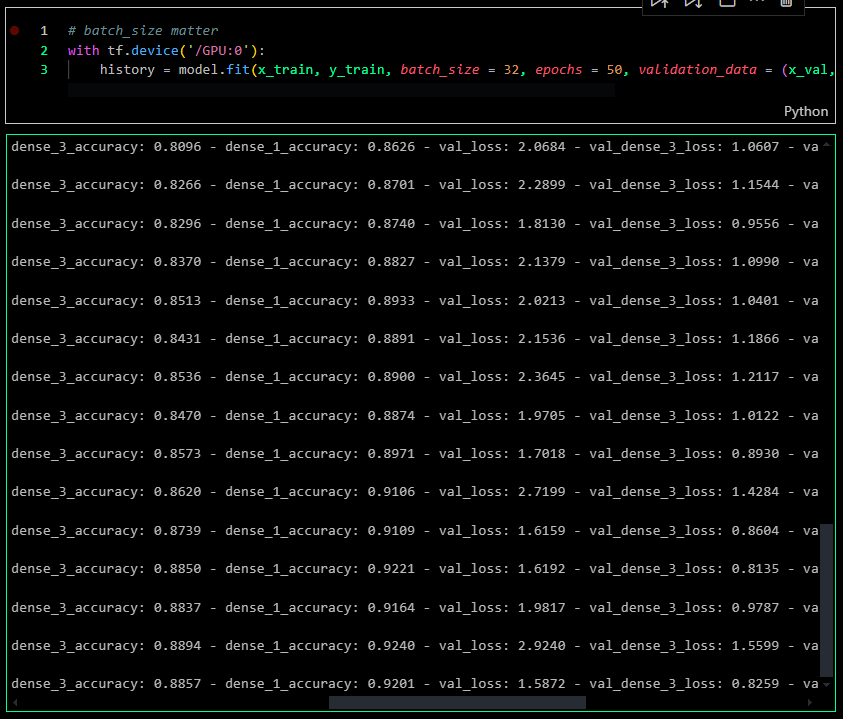
The model was tested over 50 epochs and achieved an accuracy of over 0.80 OR 80%.
-
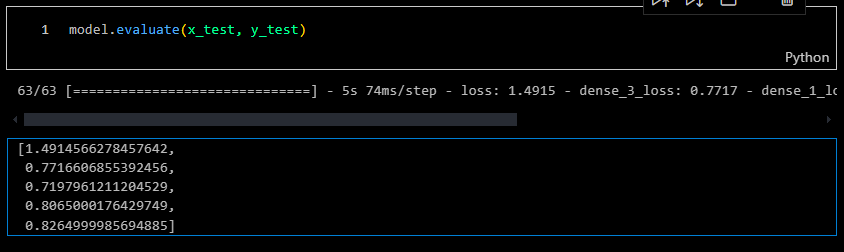
I evaluated the model using the test samples, and the results confirmed an accuracy of over 0.80 or 80%.
-
-
Filter & Feature Map Check
-
Here are examples of filters produced by this deep learning model.

-
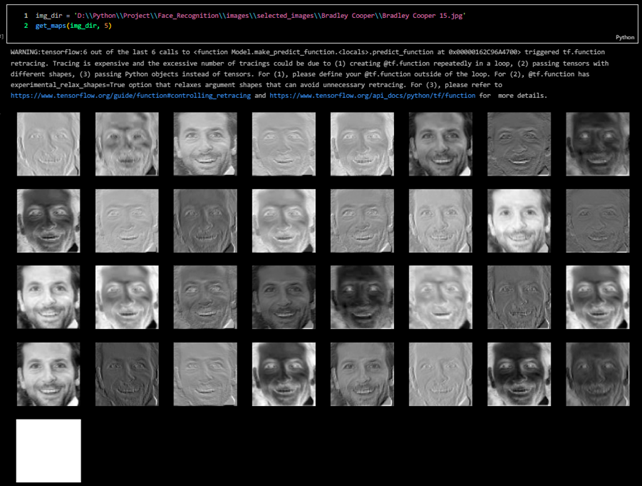
Here are feature maps generated by this deep learning model.
-
-
Testing Trained Model
I created test images for demonstration purposes as a benchmark for my actual accuracy.
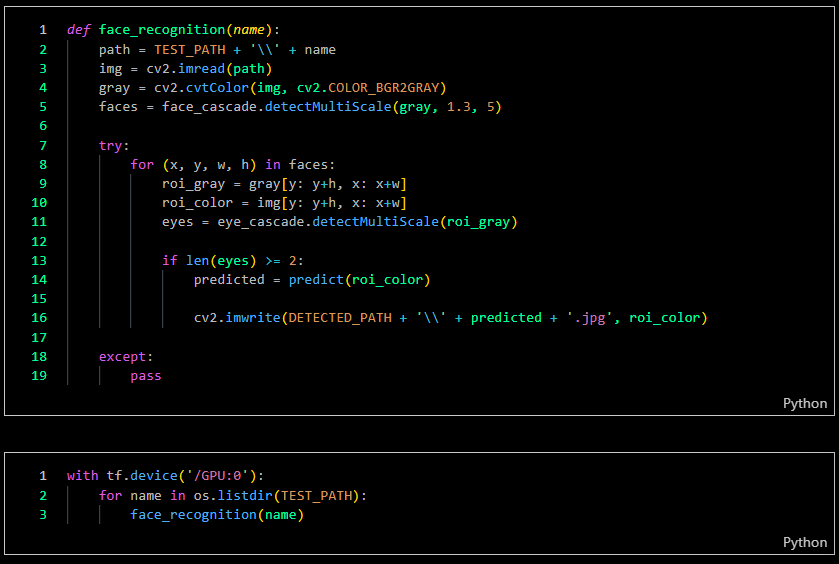
The results reveal that the facial recognition is not perfect, as illustrated by the screenshots below which trained for 80 % accuracy only. You can see that the facial images serve as the input tensor, while the filenames represent the output tensor of the detection.

Challenges
- Data Collection Speed: The data collection was very slow due to the use of a single bot. Therefore, I developed a multi-threaded bot that can run simultaneously.
- Network Constraints: Network limitations can affect image data quality and potentially cause crashes. Hence, I need to limit the number of bots running the process.
- Scalability: Managing and processing large datasets of facial images while maintaining high performance and accuracy.
- Diverse Conditions: Handling variations in lighting, facial expressions, and angles to ensure reliable recognition in different environments.
- Model Training: Training the model with a diverse and comprehensive dataset to avoid bias and ensure that the model generalizes well to unseen faces.
Insights
- Parallel Processing: Techniques like parallel computing can enhance performance by executing multiple operations simultaneously.
- Convolutional Neural Networks (CNN): CNNs are vital for extracting complex features from facial images. They can automatically learn hierarchical features, such as edges, textures, and patterns, from raw pixel data. In facial recognition, deeper CNN layers capture high-level features like facial shapes, eyes, and noses.
- Multiscale and Multiview Features: To address variations in facial expressions, skin tones, feature sizes, angles, and lighting, extracting features at multiple scales and viewpoints can significantly improve recognition accuracy.
- GPU Acceleration: Graphics Processing Units (GPUs) significantly speed up the training and inference processes for deep learning models.
- System Optimization: Regular optimization and updates of algorithms and hardware are essential to maintain real-time performance as the system scales.
Future Plans
- Diverse Data Collection: Gather data from a variety of sources to capture different facial expressions, ages, ethnicities, and lighting conditions. This helps in building a more comprehensive and unbiased model.
- Data Augmentation: Apply techniques such as image rotation, scaling, and color adjustment to artificially expand the training dataset and enhance the model's generalization.
- Improve Accuracy: Continuously refine the model by incorporating advanced deep learning techniques and expanding the dataset to enhance recognition accuracy and robustness.
- Integration with Applications: Develop integration solutions for various applications, such as security systems, personalized services, and enhanced customer experiences.
- Scalable AI Solutions: Leverage AI platforms that offer scalable and flexible solutions, allowing you to adjust resources on demand.
Real-World Use Cases
- Secure Identity Verification Systems: This model can serve as the core engine for secure access control systems in workplaces, airports, and financial institutions, helping to verify identities quickly and reliably while enhancing user convenience and system security.
- Assisting in Finding Missing Persons: Leveraging the model in public surveillance systems or mobile apps can aid in identifying missing individuals or victims of trafficking in a responsible and ethical framework, in collaboration with law enforcement.
- Research and Education in AI & Computer Vision: As a pilot project, this model is an accessible and scalable foundation for academic institutions or research groups to explore convolutional neural networks, object detection, and other computer vision applications.
- Expanding Beyond Facial Recognition: The algorithmic foundation and architecture can be repurposed or extended to recognize other object categories—opening doors for industrial, environmental, or agricultural use cases, where visual classification and recognition are essential.